标识
中国科学院大学孙海洋副教授主持完成了“口语考试的计算机自动评分研究”(gjk2017039)。课题组主要成员:张敏、陈玮、张红晖。
正文
一、内容与方法
1.1 研究内容
本研究通过对比英语口语计算机评分和人工评分的结果和过程,探索机器评分结果的可靠性和效度,旨在为自动评分模型和算法程序的优化提供参考和建议。具体包括以下四个研究问题:
1)计算机自动评分结果和人工评分结果的一致性程度如何?
2)与人工评分相比,计算机自动评分结果的可概括化程度如何?
3)计算机自动评分体现了英语口语考试构念的哪些方面?
4)教师和考生对自动评分系统在口试评分实践中的应用有什么看法?
1.2 理论框架
笔者在现代效度理论(aera/apa/ncme 2014)、kane(1992)的效度论证理论以及ets的自动评分效度验证框架(xi et al. 2008)的基础上构建了基于论证的英语口语自动评分效验框架,如图1所示:其中英语口语自动评分的效度被定义为自动评分结果的使用或者根据自动评分结果所做的决策在多大程度上有效,该效度定义可以拆分为评估、概化、外推、解释和使用共五个层面的效度主张,每个层面效度主张的论证均采用正论和反论的方式,即寻找支持每个效度主张证据的同时寻找证据反驳可能威胁该主张的质疑,形成比较完整的论证链条。
具体来讲,评估层面的证据来自于评分信度,即机评结果与人评结果的一致性;概化层面的证据来自于机器评分成绩的概化分析结果;外推层面的证据来自于机器评分结果与考生课堂表现成绩(即考生在现实生活中的语言表现)的对比;解释层面的证据来自于机器评分特征与考试构念及教师评分依据的对比;使用层面的证据来自于考生、教师及测评专家等考试相关人员对机器评分的看法以及机器评分结果对考生和教师的影响(即自动评分的反拨效应)。五个层面是环环递进的关系,前一个层面是后一个层面的基础和依据,最终目的是论证机器评分的结果能否应用在决策制定中。
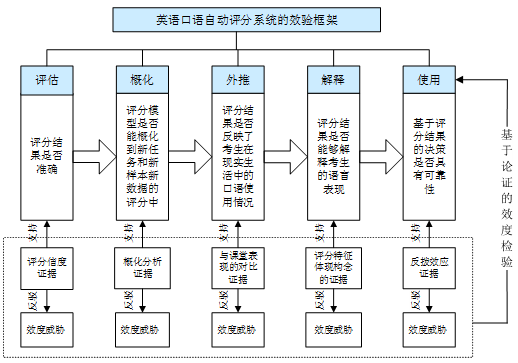
图1 基于论证的自动评分效度检验框架
1.3 研究方法
1.3.1 研究设计
根据图1所示的自动评分效度检验框架,我们设计了回答本研究四个研究问题的自动评分和人工评分实验,分别对应该框架中的评估、概化、解释和应用四个层面的效度证据:通过对比机器评分和人工评分评估机器评分结果的准确性和概化程度,通过对比机器评分特征和人工评分所使用的评分标准确定机器评分对口语考试构念的体现程度,通过调查学生和老师对机器评分结果的看法了解机器评分的应用前景。
1.3.2 研究工具及参与者
1.3.2.1 机助口试及考生
为了验证机器评分的效度,我们首先需要设计一项计算机辅助口试,其结果可以打包录音供自动评分系统评阅。考虑到研究和教学的双重目的,我们设计了一项针对研究生的通用学术英语口语测试,旨在考查学生是否满足研究生学习和科研的口语能力要求。我们借鉴了bachman & palmer(1996)的交际语言能力模型和luoma(2004)的语言结构框架(linguistically-oriented framework),将此项口试的构念定义为“考生在通用学术情境中理解他人以及表达自己的能力”:理解他人的能力体现在考生对录音内容的反应,表达自己的能力体现在就特定学术相关话题在指定时间内清晰、连贯、准确地表达自己的观点。根据这个构念定义,结合以往口语自动评分研究中以及大型高风险学术测试中所涉及的口试任务,我们最终选取朗读、复述和口头陈述作为本次口试的任务类型。
口试采用机助方式在学校语音实验室举行,实施机助口试的软件系统我们采用的是科大讯飞公司开发的fif测试平台,考试时间大约为10分钟左右。来自北京某高校非英语专业研究生一年级6个班共206名学生参与了本次口语测试,其中男生126名,女生80名;大部分被试(186名)年龄在25岁及以下,17名被试年龄在26~30岁之间,3名被试年龄超过30岁。参加口试时被试正在选修英语高级听说课程,该考试仅作为学生的口语训练素材。
1.3.2.2 自动评分软件及评分过程
本研究所使用的自动评分软件是科大讯飞公司开发的fif评分系统。据讯飞的“口语自动评分原理说明”显示,该系统共包含3个模型:(1)语音识别模型,用于识别被试的话语;(2)标准发音模型,用于判断发音准确度;(3)通用分数映射模型,该模型通过收集大量按照题型区分的口语测试数据提取了评分维度特征,并聘请专家对口试录音进行评分,基于svm(support vector machine)分类器和非线性回归映射算法,实现维度特征到人工评分(整体分)的高精度映射,也可以实现特征到单项分(如发音、流利度等)的映射。对于朗读、跟读等封闭式口语考试任务,该系统可直接自动给分;而对于回答问题、口头陈述等开放式口试任务,系统需要先定标,定标的依据是专家对200份考生数据的评分。
fif自动评分系统主要从以下4个维度给学生的口语表现打分,每个维度又包含若干所提取的评分特征。1)发音准确度:评分过程主要考虑单元音、双元音、单辅音、辅音丛、同化、不完全爆破等发音的准确性。2)重音:重音分为词重音和句重音判断,通过语音识别得到准确的词语和音素时间边界,通过基于基频的重音检测学生是否正确实现重读,是否重读了不该重读的单词,如人称代词、介词、连词等;是否在句中实现重音移位,以及是否有重音位置放置错误等。3)流利度:通过语音识别得到准确的词语和音素时间边界,同时得到停顿时间、漏读、回读等情况,包括不自然停顿的次数、时长,重复或更正的频次,是否运用发音技巧,如连音和失去爆破等。4)内容完整度:衡量发音相比给定文本是否存在漏读,一般以发音与给定文本重合的单字比率来表征。
考生完成所有任务的作答后,fif系统后台打包学生的口试录音进行数据清理和自动评分,评分结果于考试完成后第2天发布。每个任务的分数均采用10分制,自动评分结果仅报告每项任务的整体分。
1.3.2.3 人工评分过程及评分员
自动评分完成后我们组织3位有经验的评分员对所有学生每个口试任务的作答录音进行独立评分。在制定人工评分标准时我们参照了以往研究中以及国内外大型口语考试的评分标准,也结合了课程的口语教学目标以及讯飞自动评分系统的10分制评分等级,最终形成了5档10分制人工评分标准。我们将评分标准发送给每位评分员,并让每位评分员试评了3位学生的作答录音,确保评分员对评分标准有准确一致的理解。三位评分员各自在讯飞fif平台听考生考试录音并给考生每个任务的表现打整体分,所有评分工作于1个月内完成。
1.3.2.4 问卷调查
本研究共有两项问卷调查,一项是针对参与机助口试的考生,另一项面向高校有经验的教师评分员。考生问卷包括两部分内容:第一部分是被试的背景信息,第二部分是15道里克特量表题目,前9个题是学生对机助口试的看法,后6个题目是学生对自动评分的态度和看法。问卷的初稿由课题组成员设计,经三位任课教师审核反馈,两位其他平行班学生试做并反馈,在此基础上修订完成。参加考试的206位考生中有204位完成了所有问卷题目,因此,该项问卷的有效数据为204位考生的填答数据。
教师问卷主体部分的内容为口语自动评分系统以及以往口语评分量表中所涉及到的评分特征,要求填答教师根据自己的评分体验判断各评分特征的重要性程度。问卷由课题组成员、任课教师以及两位测试专家经多轮商讨确定框架和具体题项内容,并邀请5位评分经验丰富的教师参与试测,根据试测反馈意见再进行了修订。最终发放的问卷包括67道五级里克特量表题目,其中有关朗读任务的评分特征共21道题目;有关复述和口头陈述的评分特征均为23道题目。问卷通过问卷星编辑,由研究者通过微信定向发送给填答老师,虽然是匿名填答,但所有54位填答老师均为课题负责人所熟知的老师,他们是来自各高校的英语教师,其中10位男教师44位女教师,均有丰富的教学和口试评分经验。
1.3.2.5 有声思维
为了了解教师在给学生打分过程中的思维过程,对比机器评分和人工评分所用的评分特征,为“解释”层面的效度主张提供证据(或反驳证据),我们还开展了评分过程的有声思维实验。5位有丰富评分经验的教师参与了有声思维,对3段(每个任务1段)口试录音打分并讲出了自己打分的依据和理由,3段口试录音均为机器评分结果和人工评分结果差异较大(分差大于3)的考生作答录音。在实验开始前,每位教师接受了有声思维培训,以确保每位老师熟悉有声思维的整个流程。
1.3.3 数据分析
对于机器评分的准确性,我们运用spss 16.0分析机评与人评结果的均值差异、评分一致率和一致性程度(相关系数),采用facets对机评分数和人评分数分别做多侧面rasch模型分析,了解各自的严厉度、内在一致性以及与考生和任务的偏差比例。
对于机器评分结果的概化程度,本研究运用genova 3.6分别对机评分数和人工分数进行了概化分析,对比了两者的概化系数和可靠性系数,以此来判断机评分数相对于人评分数的概化程度。
有关机器评分对考试构念的体现程度,我们对教师问卷和教师有声思维数据进行了分析,其中问卷数据采用spss 16.0分析,有声思维数据采用质性方法分析,将教师评分过程中的重要依据进行分类,提取典型的特征,将之与机器评分模型参数对比,以判断人工评分依据是否已纳入模型参数,了解讯飞口语智能评分系统的打分模型参数在多大程度上体现了评分标准中的构念组成。
对于口语智能评分系统的可能应用前景,本研究主要通过对参加计算机辅助口语考试的考生进行问卷调查以及对评分教师进行访谈了解学生和教师对机器评分可靠性及应用前景的看法。
二、结论与对策
2.1 研究结果
本研究数据分析的主要结果如下:
1)与人工评分相比,机器对朗读的评分偏高,对复述的评分偏低,与这两个任务有显著的偏差作用;而口头陈述的机评和人评分数比较接近,两者的一致性和一致率均比较高,评分层面的效度主张得到部分验证。
2)虽然人评分数的概化系数和可靠性系数不理想,但机评结果的概化系数和可靠性系数均比人评结果低,概化层面的效度主张没有得到验证。
3)人工评分员在评阅朗读任务时所重视和依赖的大部分特征都在讯飞fif自动评分系统所提取的评分特征中有所体现,“富有表现力”、“有感情地朗读”等比较重要的韵律特征fif评分系统目前还不能提取;此外,该系统并未明确公开其在评阅复述和口头陈述时所提取的有关“词汇”、“语法”、“内容”等维度的特征,解释层面的效度主张得到部分验证。
4)评分教师认为机器评分可以用于学生的口语训练中;学生对机器评分的客观性和可靠性存在一些质疑,但对自动评分技术未来的发展充满信心,应用层面的效度主张得到部分验证。
2.2 研究启示
要想提高机器对朗读任务评分的准确性和可靠性,技术开发者一方面要调整现有的算法,真正将与发音有关的诸如发音准确性、重音、流利度等特征体现在评分算法中,另一方面要将朗读的韵律特征纳入特征提取和算法程序中。
若要提高复述任务的评分准确性,我们认为可以将听后复述改为读后复述,这样就可以避免被试因听不懂而影响口头表达。若不改变任务形式,那该系统的使用者在考试前就需要让被试熟悉这种形式,对被试进行更多相关能力的培训。
既然机器与人工评分员对口头作文的打分一致率和一致性均比较高,那么在评阅该项任务的口试录音时机器评分可以作为人工评分的辅助,充当一个评分员的角色,与人工评分员形成双评或多评的模式,机器一评,人工二评,一评和二评分差太大诉诸仲裁进行三评,这样可以节省人力,也可以在保证评分可靠性的基础上提高评分效率。
三、成果与影响
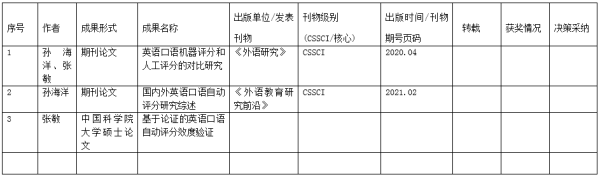
本研究已发表和确定即将发表的成果为两篇cssci期刊论文,其中“英语口语机器评分和人工评分的对比研究”发表在外语类核心期刊《外语研究》2020年第4期,“国内外英语口语自动评分研究综述”即将发表在《外语教育研究前沿》2021年第2期。
“英语口语机器评分和人工评分的对比研究”是国内语言学界第一篇运用传统测量理论和现代测量理论比较口语机器评分结果和人工评分结果的实证研究论文,实验设计细致,数据详实,研究结果可信。该论文为语言教师和语言测评学者研究自动评分结果的信、效度以及自动评分技术应用的可行性等问题提供了方法参考。
“国内外英语口语自动评分研究综述”是国内语言测试界第一篇系统梳理国内外口语自动评分发展历程、主要研究内容及未来发展趋势的论文。该论文有助于语言测试研究者、自动评分技术开发者和语言教师全面了解口语自动评分的核心技术及相关应用的发展脉络,有助于教师研究者寻找该领域与口语教学的接口作为研究方向;该论文也有助于技术开发者跳出具体算法技术的限制,了解语言理论、语言测试理论与评分特征的关系,寻求与语言教师的合作,寻找技术上的突破口,提高评分模型和算法的准确性。
四、改进与完善
4.1 存在的问题
本研究仅对口语自动评分的评分、概化、解释和应用四个层面的效度主张进行了验证,由于时间等各方面的原因未对外推层面的效度主张进行验证。
本研究运用效度论证理论仅对国内一项使用比较广泛的自动评分系统即科大讯飞的fif评分系统的效度进行了系统的验证,未与其他类似的评分软件进行对比和分析,因此,所得的结论可能不够全面。
此外,我们所采用的口头陈述任务是有准备的口头表达任务,即学生提前准备多个话题,临场抽到题目后再没有准备时间,这种任务虽然也有一定的挑战性,但其难度不如即时口头陈述任务。
4.2 完善建议
对于“外推”层面的效度,未来研究可以采集学生课堂讨论、回答问题等口头表达数据或者设计专门的课堂口头测试任务并邀请至少两位评分教师对学生的口语表现打分,将打分结果与自动评分结果进行对比,以验证外推层面的主张。
本研究仅使用了一个评分软件,未来研究可以选择2-3个应用比较广泛的评分软件,根据本研究构建的效度验证框架对不同软件的信度和效度进行系统的比较,以便教师、学生及其他相关人员更好地了解不同机器评分软件和应用的性能,并根据自己的需要选择适合的产品。
更多口试任务,尤其是即时口头陈述任务这种更常见的口头表达任务机器打分的效度如何需要未来研究进行系统的分析和验证。
总之,我国的英语口语自动评分特征提取技术、成绩合成算法等需要进一步提升和优化;有关自动评分可靠性、效度等测试方面的研究也需要深入开展。
课题组成果统计一览表
1.“成果形式”请注明为论文、编著、专著或教材
2.“获奖情况”请填写政府颁发的、厅局级以上的奖励,奖项名称应与课题名称对应。
3.“决策采纳”指被厅局级以上党政领导机关完整采纳吸收,并附有基本材料和相关证明。